How do you use structured document data stored in a table to render a block of HTML code? With a HTML render engine accessed via an API.
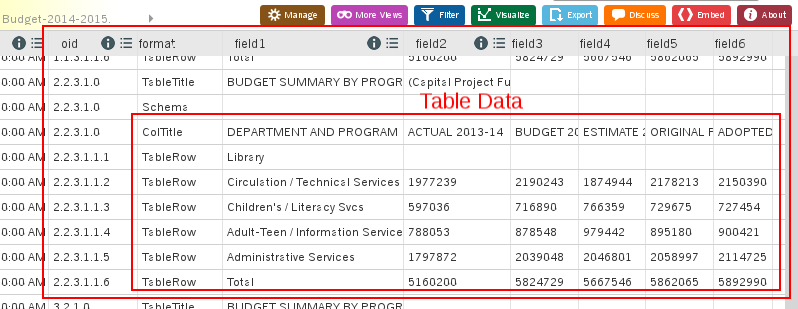
All the elements of table in a structured document will share the same base Object IDentifier or OID. In the case of the Library Budget: 2.2.3.1.
All the elements (rows) of the table can be retrieved with an API call like:
https://data.smcgov.org/resource/skc5-dd9k.type?Document_name=Budget-2014-2015.pdf&OID=2.2.3.1.
Note: this is mock-up code.
To render the table data for OID 2.2.3.1 as HTML:
https://data.smcgov.org/resource/abcd-wxyz.html?Document_name=Budget-2014-2015.pdf&OID=2.2.3.1.
Note the .html extension in the mock-up API call.
The lockup API call returns the HTML code to generate this table:
BUDGET SUMMARY BY PROGRAM: LibraryCapital Project Funds Not Included)
Sample Table Rendered CSVTo render the table data for OID 2.2.3.1 as a CSV file:
Note the .csv extension in the mock-up API call. The mock-up API call returns the table in CSV format:
OIDs and RFCsObject IDentifiers or OIDs are used extensively in the Internet's Request For Comments or RFC. They were introduced to solve the problems that complex protocols have with fixed field packet format. In a fixed field packet, each type of data has an exact sequence and size in the packet: src IP addr, dest IP addr, protocol, time to live, etc. If a packet did not need a particular field it still had to include it as null data to keep the packet format intact. As protocols became more complex the number of fields in a packet becomes large with most of the packet data being nulls because no packet uses all or even most of the fields available. The OID was introduced to allow "run length encoding" of the data in the packet. Instead of having a fixed packet format you have a packet that is a series of OID:data pairs. An OID is a dotted number, 1.2.3.4..., read left to right. Each number represents a layer in a hierarchy. An OID can either be a parent layer with child layers below it or it can be an actual piece of data with a format. For example a shared schema for OID 1.2.3.4 may define this OID as an integer or a string of text ending with a null. The sender transmitting the data walks its OID data tree to find the data's OID is 5.2.4.1 and the data type is a string. The sender transmits the data as "5.2.4.1:string". On the receiving side as the packet is received it walks the OID tree: 5 parent, 2 parent, 4 parent, 1 data object of type string. The next byte in the packet is the start of the string. The end of the string is indicated by a null, 0, byte. Once the null byte is found, the receiver knows the following byte starts the next OID. OIDs create structure in data. All the rows for a particular section of a structured document will share the same base OID. Sections, headings, tables, lists, figures. A parent OID can contain entire child OIDs of different document parts. A section may have one or more headings. The headings may contain sub-headings or tables or figures. The included parts in a section will all start with the parent's OID, 5.2.4.1, and will add more layer numbers on. For example a table in a sub-heading in a section may have an OID of 5.2.4.1.3.6. The "3" identifies this as the third sub-heading of the section. 6 indicates the sixth item in the sub-heading. All of the elements of this table will start with OID 5.2.4.1.3.6. |